Introduction¶
This article will introduce some of our attempts and practices to improve the performance of using Python to modify SImage content in Unreal Engine with TAPython. The content includes:
- Various methods to modify SImage content in TAPython
- Performance problems encountered when using
TArray<uint8>as the type of parameters to transfer data to c++ - Memory leak problem of Unreal Engine (UE5.3 and before) when using str to transfer data to c++, and solution
- Use Memory Copy to transfer data from Python to c++ in Unreal Engine
- How to use SImage to play 1080p video
The code in this article can be found in this repository. The minimum version of TAPyton required is 1.2.1beta
Problem¶
In the previous article, I introduced the method of modifying and filling the content of SImage widget in TAPython. And in this repository there is an example of using Taichi-lang and StableFuild's calculation results to fill SImage and RenderTarget.
But, we will find that the execution speed of this method is actually very slow when we use it, especially when the filled image is relatively large. For example, it takes about 1 second to fill a 2048x2048, 8-bit rgb3 channel image. This is unacceptable for real-time interaction. This is also the reason why I used a smaller resolution image in the StableFluid and "scratch card" examples. The previous version can only be said to be barely usable, and I have been looking for a faster way. There are some different attempts below, which I would like to share with you here.
Performance problem of TArray¶
The Python plugin currently used in Unreal Engine: "Python Editor Script Plugin" is a great plugin, I like it very much. However, since Python is a dynamic type language, users can store any type of element in the list and then pass it to c++. This causes the plugin to receive the list (TArray) parameter passed from the Python end in c++, and needs to judge the type of each element and then convert it. This process is very time-consuming. In the example mentioned above, we use TArray
set_image_data function declaration
void UChameleonData::SetImageData(FName AkaName, const TArray<uint8>& RawDataIn, int32 Width, int32 Height, int32 ChannelNum, bool bBGR)
im = cv2.imread(image_path) # cv2.imread will return a bgr order numpy array
...
self.data.set_image_data(self.ui_image_name, im.tobytes(), width, height, channel, bgr=True)
Attempt 1 Use compressed data¶
Due to the reason of type conversion of each element mentioned above, the most direct optimization idea is to reduce the amount of data to be transmitted, such as using compressed data.
In fact, even for images with complex content (less compression ratio), the time spent on compressing data is less than the time spent on transmitting additional data, thereby reducing the transmission time. From here, you can also see how slow the previous speed was.
@timeit
def set_image_with_uint8_compressed(self):
compressor = zlib.compressobj(level=1) # lowest compression rate, also the least compression time
compressed_data = compressor.compress(self.im_bytes) + compressor.flush()
print(f"compression ratio: {len(compressed_data) / len(self.im_bytes) * 100:.2f}%")
self.data.set_image_data(self.ui_image_name, compressed_data, self.w, self.h, self.channel, True)
Attempt 2. Use Base64 encoded string¶
Once we know that the bottleneck of the slow speed is: the element-by-element judgment and conversion process of the UE Python plugin. So if we can pass the data to c++ in an object way, then we can overcome this problem. After trying Struct and UObject, I found that using these objects is invalid, and there will be the same time-consuming when assigning their properties.
So, I thought of the Base64 String, using a complete String as the data transmission method of the image. This can not only transfer larger data, but also skip the time-consuming type check. At the same time, the additional operation time of the Base64 conversion process on the Python side and the c++ side can also be accepted. So there is in ChameleonData:
UFUNCTION(BlueprintCallable, Category = Scripting)
void SetImageDataBase64(FName AkaName, const FString& Base64String, int32 Width, int32 Height, int32 ChannelNum = 4, bool bBGR = true);
def set_image_with_base64(self):
self.im_base_64_str = base64.b64encode(self.im_bytes).decode('ascii')
self.data.set_image_data_base64(self.ui_image_name, self.im_base64_str, self.w, self.h, self.channel, True)
In fact, even if we transmit an additional 33% of the data, the performance of this method is still very good (14.5x faster), which makes it almost regarded as the solution to this problem.
But, on the second day of adding this method, I found the memory leak problem of UE's Python when calling the BlueprintCallable method.
Memory leak¶
Reproduction steps:¶
- Add a BlueprintCallable function in BlueprintLibarary, the function can do nothing.
UFUNCTION(BlueprintCallable, Category = Scripting)
static void BigStr(const FString& Base64String) {};
- Call the function through the Python command line window. Passing in a large string for observing memory changes, the following code will cause an increase of more than 100M in memory.
unreal.MyBPLib.big_str('a' * 1024 * 1024 * 50)
- In fact, the size of the string does not affect the memory change. Even if the function is called repeatedly, the memory will increase even if the string is small
- If you don't use the Python command line in the editor, and execute the corresponding Python code through
IPythonScriptPlugin::Get()->ExecPythonCommand, the memory will also increase - UE4.27, UE5.2, UE5.3 can all reproduce this problem
Fix¶
After raising this issue to the Epic team, they quickly came up with a fix.
A new Struct FFunctionStackOnScope is added to the plugin, which is used to clear temporary variables when destructing.
I believe that in the next version of UE, this submission will be merged into the official version. Before that, friends who have encountered the same problem can refer to and use it.
Attempt 3. Memory Copy¶
If we can tell c++ the memory address and length of our data, then we can avoid the time-consuming type conversion.
In Python, whether OpenCV (cv2) or PIL, the image exists in the form of numpy.ndarray. And the ctypes.data attribute of the ndarray object is a memory address that points to the array data. This memory address can be passed to the c++ function for memory copy.
For example, in the following code, we pass the memory address (im.ctypes.data) and data length (size) to c++.
This method has also become the current best practice, speeding up 100 times. (1013.011ms -> 10.001ms)
Note
Different machines will have time differences, generally around 70-100 times
@timeit
def on_memory_click(self):
im = self.im
# im = np.ascontiguousarray(im, dtype=np.uint8)
size = self.w * self.h * self.channel
self.data.set_image_data_from_memory(self.ui_image_name, im.ctypes.data, size, self.w, self.h, self.channel, True)
The implementation of this set_image_data_from_memory function in c++ is as follows, hope it can help the development of other plugins.
void UChameleonData::SetImageDataFromMemory(FName AkaName, const int64& Address, const int64& Length, int32 Width, int32 Height, int32 ChannelNum, bool bBGR /*true*/) {
const int64 ExpectedLength = Width * Height * ChannelNum;
if (Length != ExpectedLength) {
UE_LOG(PythonTA, Error, TEXT("SetImageDataFromMemory failed, data length: %d != %d * %d * %d, which should be: %d @ %s"),
Length, Width, Height, ChannelNum, ExpectedLength, *AkaName.ToString());
return;
}
uintptr_t Addr = static_cast<uintptr_t>(Address);
TArray<uint8> Data;
if (Length > 0) {
char* SourceAddr = reinterpret_cast<char*>(Addr);
if (SourceAddr) {
Data.SetNumUninitialized(Length);
FMemory::Memcpy(Data.GetData(), reinterpret_cast<uint8*>(SourceAddr), Length);
}
}
if (!Data.IsEmpty()) {
SetImageData(AkaName, Data, Width, Height, ChannelNum, bBGR);
}
else {
UE_LOG(PythonTA, Error, TEXT("SetImageDataFromMemory failed, address: %d, @ %s"), Addr, *AkaName.ToString());
}
}
Of course, we need to pay attention to the legality of the address and the continuity of the memory. In many operations of numpy, the actual data in data will not be modified. Therefore, when we do some operations on the image, such as rotation, clipping, scaling, etc., we need to call np.ascontiguousarray to ensure the continuity of the memory.
In addition to images, other large data can also be transmitted through ctypes in a similar way, such as the long string of Base64 encoding mentioned above.
NOTE
It is worth noting that strings in Python are immutable, and when transmitting strings, you need to call ctype.create_string_buffer for it and use it for transmission.
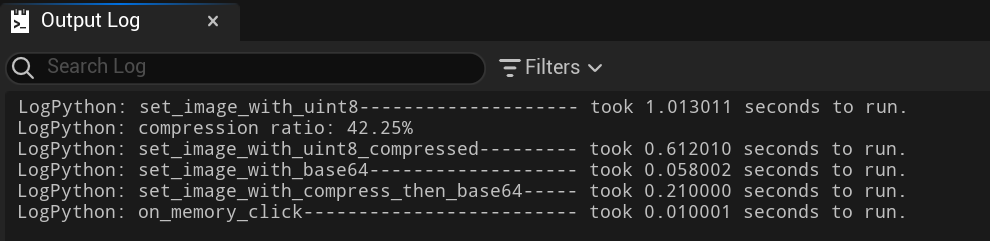
Time consumption¶
| set_image_data | set_image_data compressed | set_image_data_base64 | set_image_data_from_memory | |
|---|---|---|---|---|
| time(ms) | 1013.011 | 612.010 | 58.002 | 10.001 |
| note | compression ratio 42.25% | Best |
Video playback¶
After using the set_image_data_from_memory method above, the data transmission time has been reduced to a minimum. On my computer, when modifying SImage with 2048x2048 3-channel 8-bit image content, it takes about 10ms. We can even use the SImage widget to play back 1920*1080 60 frames of video.
In actual applications, we will be able to dynamically play, update dynamically generated content such as Stable Fluid effects.
def on_tick(self):
# the max fps is limited: 60
# set "LogOnTickWarnings=False" in config.ini, if you see the warnings
if self.cap:
ret, frame = self.cap.read()
if ret:
self.data.set_image_data_from_memory(self.ui_image_name, frame.ctypes.data
, frame.shape[0] * frame.shape[1] * frame.shape[2]
, frame.shape[1], frame.shape[0], 3, True)
else:
self.cap = None
def on_play_video(self):
if not self.cap:
if os.path.exists(self.video_path):
self.cap = cv2.VideoCapture(self.video_path)
else:
unreal.log_warning(f"video_path: {self.video_path} not exists")
def on_stop_click(self):
if self.cap:
self.cap.release()
Other Tips¶
- The order of the images read by Image.open and cv2.imread is different
Image.open is read in RGB order
self.im_rgb = np.asarray(Image.open(image_path)) # Image will return a rgb order numpy array
cv2 is read in BGR order
self.im = cv2.imread(image_path) # cv2.imread will return a bgr order numpy array
In the previous version, the speed of using bgr=True will be faster than bgr=False, but in the latest version, this problem has been fixed
Using 4-channel data will be slightly faster than 3-channel data. The reason is that SlateImageBrush uses 4-channel data
Reference¶
https://docs.python.org/3/library/ctypes.html#ctypes.create_string_buffer
TAPython_Taichi_StableFluid_UE5 repo
Modify SImage content and Set Pixels to RenderTarget in Unreal Engine
{kind=link}