介绍¶
本文将介绍我们为了提高在虚幻引擎中使用Python修改SImage内容的性能,而做的一些尝试和实践。其中会介绍到的内容有:
- TAPython中修改SImage内容的多种方法
- 使用TArray
作为参数的类型,将数据传输给c++时会遇到的性能问题 - 在使用str将传输数据给c++时,Unreal Engine(UE5.3之前,含)的内存泄漏问题,以及解决方案
- 使用Memory Copy的方式,在虚幻引擎中将数据从Python传输给c++
- 使用SImage播放1080p视频的方法
本文中的代码可以在这个仓库中找到。需要的最低的TAPyton版本是1.2.1beta
问题¶
在之前的文章我介绍过在TAPython中,修改和填充SImage组件内容的方法。并且在这个仓库中有使用Taichi-lang和StableFuild的计算结果填充SImage和RenderTarget的例子。
但是,我们在使用的过程中会发现,这个方法的执行速度实际上是非常慢的,特别是当填充的图片比较大的时候。例如,填充一个2048x2048,8位rgb3通道的图片,需要大约1秒的时间。这对实时的交互来说是不可接受的。这也是我在StableFluid的和“刮刮乐”示例中,使用了较小分辨率图片的原因。之前的版本只能说是勉强可用,我一直在寻找更快的方式。下面有一些不同的尝试,在这里分享给大家。
TArray的性能问题¶
目前虚幻引擎中使用的Python插件:“Python Editor Script Plugin”,是一个非常棒的插件,我很喜欢它。但是,由于Python是一个动态类型的语言,用户可以在list中存放任何类型的元素,进而传递给c++。这就导致了这个插件在c++中接收到Python端传过来的list(TArray)参数时,需要对每个元素进行类型判断,然后再进行转换。这个过程是非常耗时的。在我们上面提到的例子中,我们使用TArray
set_image_data函数声明
void UChameleonData::SetImageData(FName AkaName, const TArray<uint8>& RawDataIn, int32 Width, int32 Height, int32 ChannelNum, bool bBGR)
im = cv2.imread(image_path) # cv2.imread will return a bgr order numpy array
...
self.data.set_image_data(self.ui_image_name, im.tobytes(), width, height, channel, bgr=True)
尝试1 使用压缩数据¶
由于上面说的逐元素类型转换的原因,最直接的优化想法就是减少需要传输的数据量,例如使用压缩数据。
实际上,即使是复杂内容的图片(不容易被压缩),压缩数据所耗费的时间,也小于传输额外数据所耗费的时间,从而减少传输的时间。从这里也可以看到之前的速度有多慢。
@timeit
def set_image_with_uint8_compressed(self):
compressor = zlib.compressobj(level=1) # 最低的压缩率,也是最少的压缩耗时,默认可用zlib.compress()
compressed_data = compressor.compress(self.im_bytes) + compressor.flush()
print(f"compression ratio: {len(compressed_data) / len(self.im_bytes) * 100:.2f}%")
self.data.set_image_data(self.ui_image_name, compressed_data, self.w, self.h, self.channel, True)
尝试2. 使用Base64编码的字符串¶
既然知道速度慢的瓶颈是:UE的Python插件逐元素的判断和转换过程。那么如果我们能将数据以一个对象的方式传递个C++,那么就能克服这个问题。在尝试了Struct,UObject之后发现借助这些对象都是无效的,在它们的属性进行赋值的时候,也会有同样的耗时。
于是,我想到了Base64的String,使用一个完整String来作为图片的数据传输方式。这样不仅可以传输较大数据,而且跳过类型检查的耗时。同时,python端和c++端的Base64的转换过程的额外操作耗时也可以接受。于是在ChameleonData中就有了:
UFUNCTION(BlueprintCallable, Category = Scripting)
void SetImageDataBase64(FName AkaName, const FString& Base64String, int32 Width, int32 Height, int32 ChannelNum = 4, bool bBGR = true);
def set_image_with_base64(self):
self.im_base_64_str = base64.b64encode(self.im_bytes).decode('ascii')
self.data.set_image_data_base64(self.ui_image_name, self.im_base64_str, self.w, self.h, self.channel, True)
事实上,即使我们额外传输了33%的数据,这个方法的表现依然非常优秀(14.5x faster),使得差点被当作这个问题的解决方案。
但是,在添加这个方法的第二天,我就发现了UE的Python在调用BlueprintCallable方法时的内存泄露问题。
内存泄露¶
复现步骤:¶
- 在BlueprintLibarary中添加一个BlueprintCallable函数,函数中可以不做任何操作。
UFUNCTION(BlueprintCallable, Category = Scripting)
static void BigStr(const FString& Base64String) {};
- 通过Python命令行窗口调用该函数。传入一个大字符串便于观察内存变化,下面的代码会造成一个100+M的内存增加。
unreal.MyBPLib.big_str('a' * 1024 * 1024 * 50)
- 实际上string的大小不会影响内存变化,反复调用该函数即使小字符串,也会出现内存增加的情况
- 不使用编辑器中的Python命令行,通过
IPythonScriptPlugin::Get()->ExecPythonCommand执行对于的Python代码也会出现内存增加的情况 - UE4.27, UE5.2, UE5.3 均能复现该问题
修复¶
在给Epic团队提出这个问题之后,他们很快就给出了修复方案
一个新的Struct FFunctionStackOnScope 被添加到插件,用于在析构的时候,清除零时变量。
相信在下个UE的版本中,这个提交就会被合并到正式版本中。在此之前,有遇到同样问题的朋友可以参考和使用。
尝试3. 内存拷贝¶
如果我们能够告诉c++我们的数据的内存地址和长度,那么就可以避免类型转换的耗时。
在Python中不论OpenCV(cv2)或者PIL,图片在Python中都是以numpy.ndarray的形式存在的。并且ndarray 对象的 ctypes.data 属性是一个指向数组数据的内存地址。这个内存地址可以被传递给C++ 函数,用于内存拷贝。
例如下面的代码中,我们传递了内存地址(im.ctypes.data)和数据长度(size)给c++。
这个方法也成了目前的最佳实践,提速了100倍。(1013.011ms -> 10.001ms)
NOTE
不同的机器会有时间差异,一般会在70-100倍左右
@timeit
def on_memory_click(self):
im = self.im
# im = np.ascontiguousarray(im, dtype=np.uint8)
size = self.w * self.h * self.channel
self.data.set_image_data_from_memory(self.ui_image_name, im.ctypes.data, size, self.w, self.h, self.channel, True)
这个set_image_data_from_memory函数在c++中的实现如下,
void UChameleonData::SetImageDataFromMemory(FName AkaName, const int64& Address, const int64& Length, int32 Width, int32 Height, int32 ChannelNum, bool bBGR /*true*/) {
const int64 ExpectedLength = Width * Height * ChannelNum;
if (Length != ExpectedLength) {
UE_LOG(PythonTA, Error, TEXT("SetImageDataFromMemory failed, data length: %d != %d * %d * %d, which should be: %d @ %s"),
Length, Width, Height, ChannelNum, ExpectedLength, *AkaName.ToString());
return;
}
uintptr_t Addr = static_cast<uintptr_t>(Address);
TArray<uint8> Data;
if (Length > 0) {
char* SourceAddr = reinterpret_cast<char*>(Addr);
if (SourceAddr) {
Data.SetNumUninitialized(Length);
FMemory::Memcpy(Data.GetData(), reinterpret_cast<uint8*>(SourceAddr), Length);
}
}
if (!Data.IsEmpty()) {
SetImageData(AkaName, Data, Width, Height, ChannelNum, bBGR);
}
else {
UE_LOG(PythonTA, Error, TEXT("SetImageDataFromMemory failed, address: %d, @ %s"), Addr, *AkaName.ToString());
}
}
当然,我们需要注意地址的合法和内存的连续性。numpy的很多操作中,并不会对data中的实际数据的排布进行修改。因此,我们需要调用np.ascontiguousarray来保证内存的连续性与图片像素的顺序的一致性^_^
Of course, we need to pay attention to the legality of the address and the continuity of the memory. In many operations of numpy, the actual data in data will not be modified. Therefore, when we do some operations on the image, such as rotation, clipping, scaling, etc., we need to call np.ascontiguousarray to ensure the continuity of the memory.
除了图片,其他的较大的数据也可以通过ctypes用类似的方式传输,例如上文提到过的Base64编码的长字符串。
NOTE
值得注意的是,Python中的字符串是不可变的,在传输字符串时需要为其调用ctype.create_string_buffer,并将其用于传输。
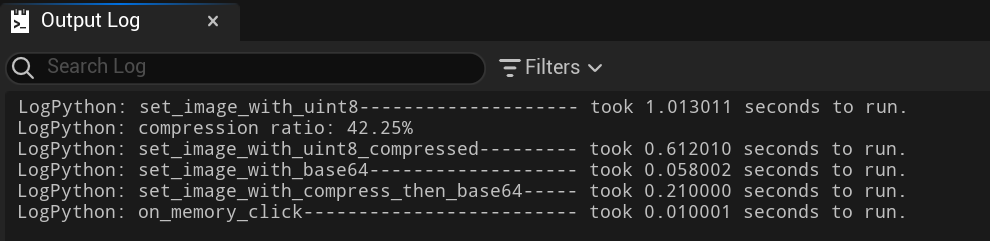
Time consumption¶
| set_image_data | set_image_data compressed | set_image_data_base64 | set_image_data_from_memory | |
|---|---|---|---|---|
| time(ms) | 1013.011 | 612.010 | 58.002 | 10.001 |
| note | compression ratio 42.25% | Best |
视频回放¶
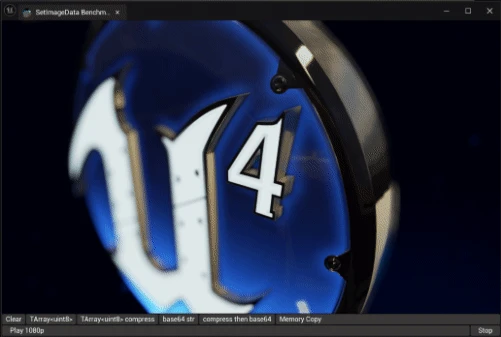
在使用上面的set_image_data_from_memory方法之后,数据传输的耗时已经降低到了最低。在我的电脑上,用2048x2048 3通道8bit的图片内容修改SImage,耗时在10ms左右。我们甚至已经完全可以用SImage这个组件来回放1920*1080 60帧的视频了。
实际的应用中,我们将可以动态播放、更新类似于Stable Fluid的效果等动态生成的内容。
def on_tick(self):
# the max fps is limited: 60
# set "LogOnTickWarnings=False" in config.ini, if you see the warnings
if self.cap:
ret, frame = self.cap.read()
if ret:
self.data.set_image_data_from_memory(self.ui_image_name, frame.ctypes.data
, frame.shape[0] * frame.shape[1] * frame.shape[2]
, frame.shape[1], frame.shape[0], 3, True)
else:
self.cap = None
def on_play_video(self):
if not self.cap:
if os.path.exists(self.video_path):
self.cap = cv2.VideoCapture(self.video_path)
else:
unreal.log_warning(f"video_path: {self.video_path} not exists")
def on_stop_click(self):
if self.cap:
self.cap.release()
其他Tips¶
Image.open 和 cv2.imread 读取的图片的顺序是不同的
Image 是以RGB的顺序读取的
self.im_rgb = np.asarray(Image.open(image_path)) # Image will return a rgb order numpy array
而cv2是以BGR的顺序读取的
self.im = cv2.imread(image_path) # cv2.imread will return a bgr order numpy array
之前的版本中,使用bgr=True的速度会快于bgr=False,但是在最新的版本中,这个问题已经被修复了
使用4通道的数据会略微快于3通道的数据。原因的SlateImageBrush使用的是4通道的数据
参考¶
https://docs.python.org/3/library/ctypes.html#ctypes.create_string_buffer
TAPython_Taichi_StableFluid_UE5 repo
Modify SImage content and Set Pixels to RenderTarget in Unreal Engine
{kind=link}